

Memungkinkan model bahasa besar (LLMs) untuk memperoleh pengetahuan baru setelah pelatihan masih menjadi tantangan besar dalam dunia AI perusahaan. Solusi yang ada saat ini cenderung mahal, lambat, atau terbatasi oleh ukuran konteks yang bisa diproses.
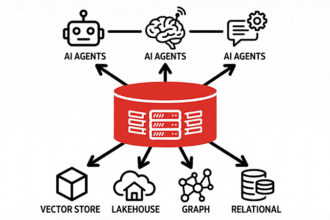
MeMo, sebuah kerangka kerja yang dikembangkan oleh para peneliti dari beberapa universitas, mengenkode pengetahuan baru ke dalam model memori kecil yang beroperasi terpisah dari LLM utama.
Arsitektur modular ini bekerja baik dengan model open-source maupun closed-source, serta menghindari kompleksitas dari pipeline retrieval-augmented generation (RAG) dan pelatihan ulang model secara penuh.
Hasil eksperimen menunjukkan bahwa MeMo dapat menangani query yang kompleks dengan andal, bahkan ketika sistem retrieval mengalami gangguan. MeMo menjauhi masalah ‘catastrophic forgetting’ yang biasa terjadi saat fine-tuning langsung dan menyediakan jalur yang ekonomis untuk pembaruan pengetahuan yang berkelanjutan.
Tantangan Memperbarui Memori LLM
Model bahasa besar umumnya ‘bebek’ setelah dilatih dan pengetahuan internalnya tetap statis sampai mereka menjalani pembaruan yang sangat mahal dan komputasional.
Saat ini, pengembang mengandalkan tiga pendekatan utama untuk mengintegrasikan pengetahuan eksternal ke dalam LLM, masing-masing dengan kelemahan yang berbeda:
- Metode non-parametrik, seperti RAG dan in-context learning, mengambil dokumen relevan dari basis data eksternal dan menyisipkannya langsung ke dalam prompt model. Meskipun populer, metode ini terbatasi oleh ukuran jendela konteks.
- Metode parametrik, seperti pretraining terus-menerus atau fine-tuning terawasi, mencoba untuk menginternalisasi pengetahuan baru secara langsung ke dalam bobot LLM. Pembaruan pada LLM yang besar ini sangat mahal dan umumnya tidak mungkin untuk model closed-source yang tersembunyi di belakang API. Fine-tuning juga rentan terhadap catastrophic forgetting.
- Metode memori laten, seperti kompresi konteks, menawarkan jalan tengah. Namun kelemahannya adalah “representation coupling,” di mana memori yang terkompresi terikat pada arsitektur model yang memproduksinya, sehingga tidak bisa dipindahkan ke model lain.
Cara Kerja MeMo
Kerangka MeMo memperkenalkan arsitektur modular dengan dua komponen terpisah. Model MEMORY adalah model bahasa kecil yang dilatih khusus untuk mengenkode pengetahuan baru. Model EXECUTIVE adalah LLM beku yang berfungsi sebagai mesin pemikiran. Ketika pengguna mengajukan pertanyaan, model EXECUTIVE memperlakukan model MEMORY sebagai orakel eksternal, mengeluarkan sub-query yang terarah untuk mengumpulkan fakta dan menyintesis fakta tersebut menjadi jawaban akhir.
Prinsip desain utama MeMo adalah konsep “reflections.” Reflections adalah pasangan pertanyaan-jawaban yang dirancang untuk menangkap setiap sudut dari korpus pengetahuan. Alih-alih memaksa AI untuk memproses dokumen besar yang tidak terstruktur, MeMo menggunakan model GENERATOR untuk mendistilasi teks mentah menjadi ribuan pasangan QA yang terfokus. Model MEMORY kemudian dilatih dengan dataset ini untuk menjawab pertanyaan tanpa perlu membaca konteks yang diambil.
Dalam tahap inference, interaksi antara kedua model mengikuti protokol tiga tahap yang terstruktur:
- Model EXECUTIVE memecah query pengguna yang kompleks menjadi pertanyaan sub-atom yang lebih sederhana. Model MEMORY menjawab setiap pertanyaan secara independen untuk menetapkan fakta dasar.
- Berdasarkan petunjuk awal tersebut, model EXECUTIVE mengeluarkan query lanjutan untuk mempersempit kandidat entitas hingga menemukan target spesifik.
- Akhirnya, model EXECUTIVE menanyakan model MEMORY tentang fakta pendukung terkait entitas target dan menyintesis potongan yang diambil menjadi jawaban yang koheren.
Arsitektur ini menggabungkan kekuatan dari tiga paradigma memori AI yang ada sekaligus menghindari kelemahan mereka. MeMo memisahkan penyimpanan memori dari proses penalaran, memastikan kompatibilitas dengan model open-weight dan closed API. Dengan cara ini, MeMo memastikan pengetahuan dapat diinternalisasi langsung ke dalam parameter, tetapi dengan pembaruan yang diisolasi pada model MEMORY yang lebih kecil untuk melindungi mesin penalaran.
Menangani Pembaruan Pengetahuan yang Kontinu
Manajemen memori AI membutuhkan pembaruan terus-menerus seiring perubahan kebijakan perusahaan dan laporan baru yang diterbitkan. Biasanya, memperbarui parameter model memerlukan pelatihan ulang dari awal. Dengan tumbuhnya basis pengetahuan, biaya pelatihan ulang menjadi tidak terkelola.
MeMo menggunakan teknik bernama “model merging.” Alih-alih fase pelatihan ulang yang besar, MeMo melatih model MEMORY baru yang independen hanya pada dokumen yang baru ditambahkan. Sistem ini menghasilkan “task vector” yang mewakili perubahan parameter yang diperoleh dari data baru. Pembaruan ini kemudian digabungkan secara matematis ke dalam bobot model MEMORY asli.
Pendekatan ini memangkas waktu komputasi yang diperlukan untuk menjaga sistem selalu up-to-date, sekaligus menghindari gangguan yang menyebabkan catastrophic forgetting.
MeMo dalam Tindakan
Untuk mengukur efektivitas di dunia nyata, tim riset mengevaluasi MeMo terhadap beberapa benchmark industri yang memerlukan penalaran kompleks dan melintasi banyak dokumen.
Mereka menggunakan Qwen2.5-32B-Instruct sebagai model GENERATOR untuk mendistilasi teks mentah menjadi reflections. Untuk model MEMORY utama, mereka menerapkan Qwen2.5-14B-Instruct, dan juga memvalidasi pendekatan ini pada model parameter 1-2B di berbagai arsitektur.
Dalam pengujian, MeMo menunjukkan kinerja yang unggul, terutama dalam penalaran dokumen panjang. Dalam benchmark NarrativeQA, MeMo mencatat akurasi 53,58% saat dipasangkan dengan Gemini 3 Flash, sementara sistem lain hanya mencapai 23,21% di tempat tertinggi.
MeMo jauh lebih terampil dalam menyintesis jawaban kompleks dalam sistem perusahaan, seperti saat harus menjelajahi kerangka regulasi yang saling tumpang tindih atau menyatukan wawasan dari basis kode besar dan dokumentasi eksternal. Sistem RAG tradisional terkendala oleh batas konteks dan gagal menghubungkan konsep yang menyebar di ratusan halaman.
Limitasi dan Trade-offs
Untuk tim rekayasa yang ingin menerapkan MeMo, ada beberapa batasan penting yang perlu diperhatikan. MeMo memerlukan biaya pelatihan di awal untuk setiap korpus baru, dan proses pembuatan dataset QA sangat mahal.
Karena model MEMORY adalah jaringan neural berukuran tetap, kemampuannya untuk menginternalisasi pengetahuan terbatas oleh kapasitas representasionalnya. Walaupun tim tidak menemukan batasan keras selama benchmarking, mereka memperkirakan bahwa korpus yang padat informasi akan lebih dari yang bisa ditangani oleh model MEMORY berukuran tetap.
Keputusan antara MeMo dan RAG bergantung pada prioritas antara “lookup” dan “synthesis,” serta volatilitas data. Secara keseluruhan, MeMo menawarkan keunggulan signifikan dalam penalaran jika korpus pengetahuan bersifat umum dan berubah perlahan.